






芯片资讯
- 发布日期:2024-01-09 12:00 点击次数:179
随着越来越多不同类型的处理元件包含在同一架构中,对处理器进行编程变得越来越复杂。
虽然系统架构师可能会陶醉于可用于提高功率、性能和面积的选项数量,但编程功能并使其协同工作的挑战将成为一项重大挑战。它涉及来自不同IP提供商的多种编程工具、模型和方法。
“在任何一种边缘推理产品中,无论是Nest相机、汽车应用中的相机,还是笔记本电脑,基本上都有三种类型的功能软件,主要来自三种不同类型的开发人员——数据科学家、嵌入式CPU开发人员和DSP开发人员,”的首席营销官史蒂夫·罗迪说二次曲面。
根据他们在开发过程中所处的位置,他们的方法可能看起来非常不同。“数据科学家花时间在Python、框架培训和数学抽象层面上做事情,”罗迪说。“PyTorch是非常高级的、抽象的、解释的,不太关心实现的效率,因为他们关心的只是数学中的增益函数和模型的准确性等。从那里出来的是PyTorch模型,ONNX代码,以及嵌入PyTorch模型的Python代码。嵌入式开发者是完全不同的性格类型。他们使用更传统的工具集,这些工具集可能是CPU供应商的工具,或者Arm工具包,或者像Microsoft Visual Studio for C/C++开发这样的通用工具。无论是哪种CPU,您都将获得该特定芯片的供应商版本的开发工作室,它将带有预构建的东西,如RTOS代码和驱动程序代码。如果你从某个特定的供应商那里购买芯片级的解决方案,它会有DDR和PCI接口的驱动程序,等等。“
例如,考虑iPhone的应用程序编程,它是高度抽象的。“iPhone开发者有一个开发工具包,上面有很多其他软件,”他说。“但在很大程度上,这是一个嵌入式的东西。有人在编写C代码,有人在开发操作系统,不管是泽法还是微软的操作系统,或者类似的东西。他们生产什么?他们产生C代码,有时是汇编代码,这取决于编译器的质量。DSP开发人员也是算法开发人员,通常面向数学家,使用MATLAB或Visual Studio等工具。这里创建了三个级别的代码。类似Python的数据科学代码,DSP,C++,还有嵌入式代码。”
从一个Android开发者的角度来看,Ronan Naughton是手臂说:“一个典型的软件工程师可能正在开发一个移动应用程序,用于部署到多个平台。在这种情况下,他们将寻求最低的维护开销、无缝的可移植性和高性能,这些都可以通过无处不在的Arm CPU和支持工具链来提供。”
在Android环境中,针对CPU的编程提供了尽可能多的工具选择。
“例如,”诺顿指出,“一个好的矢量化编译器,如LLVM或GCC,可以针对多个CPU和操作系统目标。有一个丰富的面向特定功能任务的函数库生态系统,例如面向ML的Arm计算库。或者,开发人员可以使用Arm C语言扩展等内部函数来针对指令集架构本身。”
在所有这些之下是一个传统的架构,由一个NPU、DSP和CPU组成,需要所有的步骤才能到达目标主机CPU。所有或大部分都使用某种形式的运行时应用程序。
“如果你正在运行你的机器学习代码,CPU会积极参与每一次推理,每一次迭代,每一次通过机器学习图编排整个事情,”罗迪指出。
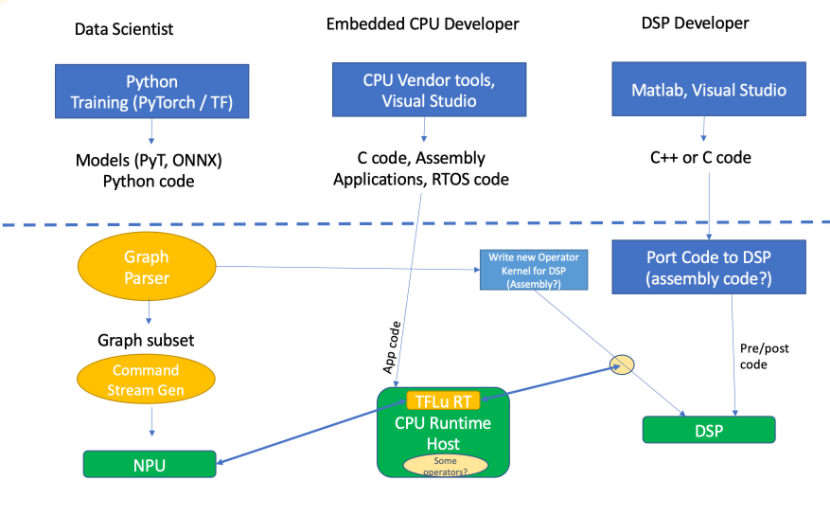
图1:传统NPU+DSP+CPU的工具/代码流程。来源:Quadric.io
DSP、CPU和npu的编程方式因应用、用例、系统架构和环境而异。这将决定如何优化代码,以实现特定应用程序或使用模型的最佳性能。
“在CPU上,大多数编译器可以非常好地优化代码,但当编程DSP或npu时,特别是并行化代码时,大量工作必须由软件工程师完成,因为所有编译器都失败了,”Andy Heinig说,他是弗劳恩霍夫协会适应性系统工程分部。这意味着硬件上的并行工作越多,软件工程师手动完成的工作就越多。而且大部分工作都是低级编程需要的。”
虽然有一些重叠,但这些不同的处理元素之间也有一些基本差异。“CPU是一种通用架构,因此支持广泛的用途、操作系统、开发工具、库和许多编程语言,从传统的低级C到高级C++、Python、Web应用程序和Java,”的产品经理盖伊·本哈姆说新思科技。“DSP应用通常运行在优化的实时系统上,因此对DSP处理器进行编程需要使用低级语言(如汇编语言、C语言)、DSP库和特定的编译器/分析器,以实现数据并行、性能调整和代码大小优化。与通用CPU不同,但与DSP类似,NPU架构也致力于加速特定任务,在这种情况下是为了加速AI/ML应用。”
DSP架构可以并行处理来自多个传感器的数据。传统的CPU或DSP编程依赖于一个程序或一套规则的算法来处理数据,而人工智能则从数据中学习,并随着时间的推移提高其性能。
“人工智能使用PyTorch和TensorFlow等高级框架来创建、训练和部署模型,”本哈姆解释道。“神经网络模型的灵感来自人脑中神经元的结构,由一个系统的数学表示组成,该系统可以根据输入数据进行预测或决策。”
还有其他不同之处。Tensilica Vision和AI DSPs的产品营销和管理小组主任Pulin Desai说,除了用C和C++等高级语言编程之外节奏,“DSP和CPU还利用各种库,如math lib、fp lib。DSP也有一个特定的库,用于特定的垂直领域,以执行特殊用途的应用。DSP和CPU还可以与OpenCL和Halide等高级语言一起工作,客户可以使用这些语言来开发他们的应用。”
NPU编程是在完全不同的环境中使用AI训练框架完成的。反过来,它们在TensorFlow和PyTorch中生成神经网络代码,并使用神经网络编译器为特定硬件进一步编译网络。”
“神经网络不是‘程序化的’“他们受过训练,”新思科技的产品经理戈尔登·库勃说DSP和CPU以更传统的方式编程。代码是用C/C++写的。然后,您需要一个IDE和调试器来测试和编辑代码。“
编程模型如何工作
所以对于CPU和DSP,设计师会用C或C++编程,但可能会调用特定的lib api。“例如,对于vision,代码可能会调用OpenCV API调用,”Desai说。
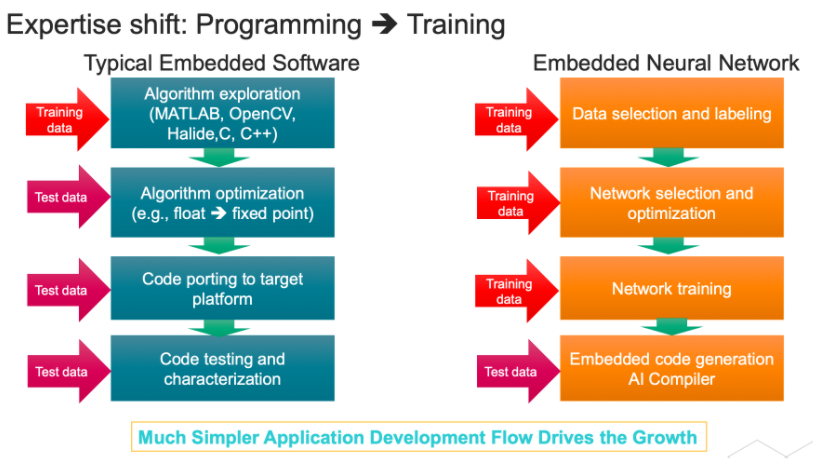
图2:DSP/CPU与npu上嵌入式软件开发的比较。来源:Cadence
Fraunhofer的Heinig说,大多数时候,优化代码的工作是手工完成的。“当涉及到并行使用硬件时,高级编程模型通常会失败。但是,当然, 电子元器件采购网 使用具有基本高度优化功能的库是可能的。”
开发一个人工智能模型是非常不同的。需要几个步骤。“首先是识别和准备,”新思科技的本哈姆说。“在确定适合由人工智能解决的问题后,选择正确的模型并收集将在该过程中使用的数据非常重要。其次是模特培训。训练模型意味着使用大量的训练数据来优化模型,提高性能并确保准确性。第三是推理。人工智能模型部署在生产环境中,用于根据可用数据快速做出结论、预测和推断。”
还有其他不同之处。大多数DSP都是矢量处理器,其架构针对高效并行处理数据阵列进行了调整。“为了有效地使用硬件,数据需要矢量化,”新思科技高级产品经理Markus Willems说。“当从标量代码开始时,优化编译器可以应用某种程度的自动向量化。然而,对于绝大多数用例来说,获得最佳结果需要程序员使用专用的矢量数据类型,以矢量化的方式编写代码。”
Willems建议,为了充分利用指令集的全部功能,通常使用内部函数。与普通的汇编编码不同,内建函数将寄存器分配留给编译器,这允许代码重用和移植
此外,对于大多数DSP算法,设计从MATLAB开始分析功能性能(即检查算法是否解决了问题)。对于越来越多的DSP,有一种直接的方法可以将MATLAB算法映射到矢量化DSP代码,即使用MATLAB嵌入式编码器和处理器专用DSP库。
但为了充分利用处理器,海尼格说,有必要共同优化硬件和软件。否则,你的解决方案将会失败,因为你意识到设计的硬件并不完全符合问题规范时已经太晚了。如果要并行执行越来越多的操作,尤其如此。”
对于一个SoC架构师来说,它从什么是目标市场和目标应用开始,因为这将驱动硬件和软件架构。
“在可编程性和固定硬件之间做出选择总是一个挑战,”Desai解释道。“决策是由成本(SoC面积)、功耗、性能、上市时间和未来需求驱动的。如果您了解您的目标应用,并希望优化功耗和面积,固定硬件是最佳选择。一个例子是H.264解码器。]神经网络是不断变化的,因此可编程性是必须的,但一种架构,其中一些功能在固定功能(硬件加速器,如NPU)中,一些在可编程CPU或DSP中,是人工智能的最佳选择。”
划分处理
所有这些都变得更加复杂,因为不同的设计者/程序员可能负责不同的代码。
“我们在谈论推理应用,但我们也在谈论一个系统公司制造一个系统,”德赛说。“由于SoC是通用的,可能会有人工智能开发人员开发特定的神经网络来解决特定的问题,例如,为麦克风降低噪声的降噪网络,为安全摄像头提供人员检测网络等。这个网络需要转换为可以在SoC上运行的代码,因此您将拥有知道如何使用工具将神经网络转换为可以在具有CPU/DSP/NPU的SoC上启动的代码的程序员。但是,如果是实时应用程序,您还需要知道如何使用实时操作系统、处理器级系统软件等的系统软件工程师。此外,如果这是消费类设备,可能会有高级软件开发人员开发GUI或用户界面。”
对于NPU,有几个注意事项。“首先,NPU必须设计为加速人工智能工作负载,”本哈姆说。“人工智能/神经网络工作负载由深度学习算法组成,这些算法在许多层中需要大量的数学和多重矩阵乘法,因此需要并行架构。”
他解释说,一个好的NPU的关键特征之一是处理数据和快速完成操作的能力,性能以TOPS/MAC衡量。“功率/性能/面积(成本)之间的典型半导体权衡也与NPU设计密切相关。对于自动驾驶汽车的使用,NPU的延迟是至关重要的,特别是当决定何时踩下汽车刹车是生死攸关的事情时。这也与功能安全设计考虑有关。设计团队还必须考虑NPU设计是否符合安全要求。”
程序员需要考虑的另一个关键问题是开发和编程工具。
“如果没有合适的软件开发工具,能够轻松地从流行的人工智能框架中导入NN/AI模型,编译,优化它,并自动利用包括内存设计考虑在内的NPU架构,那么构建一个伟大的NPU是不够的,”他说。“提供一种检查模型准确性的方法以及模拟工具也很重要,这样程序员可以在硬件存在之前就开始软件开发和验证。这是上市时间的一个重要考虑因素。”
库珀同意了。“npu比DSP更接近于定制加速器,尤其是GPU或CPU,它们完全灵活。您可能不会选择添加NPU,除非您在相当长的时间内强烈需要NN性能。我们的客户只需要一点点人工智能,他们使用矢量DSP来实现DSP性能,并在需要时对其进行重新配置以处理人工智能,从而确保其芯片面积的最大灵活性。这很好,但不会像专用NPU那样节能或节省面积。”
最后,当试图确定图的哪些子集适合NPU,哪些不适合时,编程挑战就来了。[参见上面图1的左侧]
Quadric公司的罗迪说:“如果它不运行,它就必须在别的地方运行,所以代码必须被拆分。”与此同时,还有一个存储在内存中的辅助命令流生成器或链表生成器,NPU知道足够多的信息来获取它的命令。虽然这一部分非常简单,但是所有不在系统上运行的部分呢?那些运营商该往哪里跑?有没有已经存在的机器学习操作符的高效实现?如果是,它是在DSP上,还是在CPU上,如果它不存在?必须有人去创造一个新的版本。你在DSP上这样做是因为你希望它具有高性能。现在你必须在DSP上编码,很多DSP缺乏好的工具,尤其是那些专门为机器学习而构建的工具。通用版本的DSP——音频DSP或基本通用DSP——可能有两个MAC或四个MAC类型的东西。为机器学习而构建的DSP将是非常广泛的DSP。超宽DSP可以成为非常广泛的激活和标准化以及数据科学中发生的事情的良好目标,但它们是新的,因此可能没有可靠的编译器。”
结论
在过去,这些编程世界是独立的学科。但随着人工智能计算越来越多地包含在设备中,以及随着系统变得越来越异构,软件开发人员至少需要更多地了解其他领域正在发生的事情。
最终,这可能成为单一硬件/软件架构的驱动因素,允许工程团队编写和运行复杂的C++代码,而不必在两三种类型的处理器之间进行划分。但是,如果要做到这一点,从现在到那时还有许多工作要做。鉴于人工智能和硬件架构的发展速度,尚不完全清楚该架构在准备就绪时是否仍然相关。
审核编辑:黄飞
- 芯片供应链在人工智能和电子制造中的重要角色2025-04-28